


















 14 / 33
14 / 33

13
4. Descripción del algoritmo
Para el mecanismo para generar la voz del sistema
UrbvoxTTS
se implementó la metodología de síntesis por
concatenación ya que es el más usado debido a que ofrece mayor flexibilidad y una buena calidad de voz lo
cual resulta significativo para los fines específicos del proyecto.
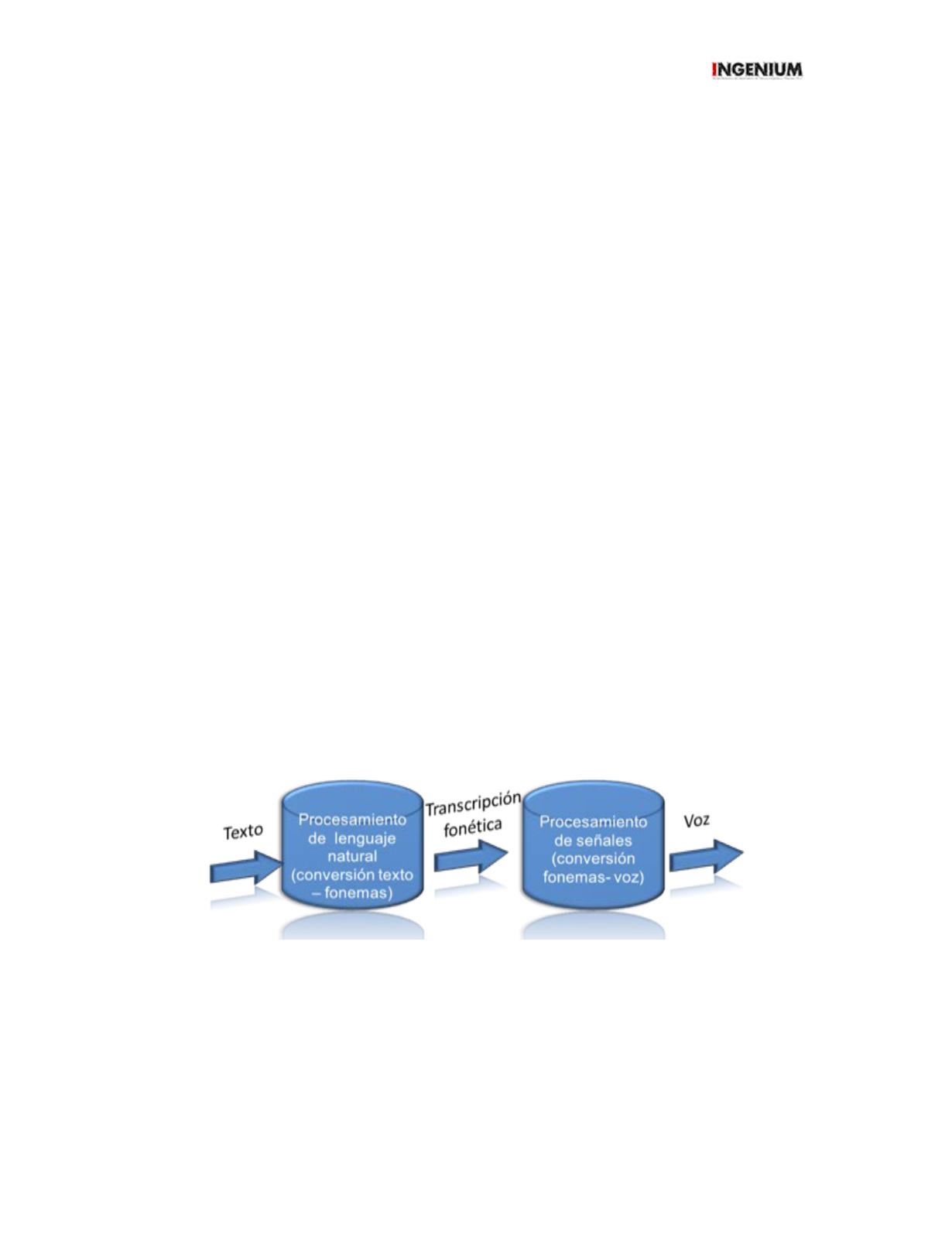
El funcionamiento de la síntesis por concatenación se resume en las siguientes etapas:
Conversión texto-fonemas:
La primera parte de un sistema de síntesis de voz es obtener el texto y
generar la secuencia de fonemas que se requieren para generar la salida de voz como información acerca del
lugar en que cada una de las palabras se encuentra acentuada.
Se aplican reglas básicas para obtener los fonemas a partir de las letras. Para llevar a cabo este
proceso se va tomando palabra por palabra y si se encuentran símbolos o números estos deben ser eliminados,
reemplazados por pausas o reemplazados por palabras según se requiera.
Una vez que se ha obtenido la secuencia de fonemas a reproducir es necesario encontrar la sílaba que
lleva el énfasis dentro de la palabra, llamada sílaba tónica, identificada por un acento escrito o prosódico,
mediante la aplicación de reglas de acentuación. Una vez que la palabra está lista puede ser enviada al
siguiente módulo.
Conversión fonemas-voz:
Para un sistema por concatenación se requiere como primer paso el generar
la base de datos de segmentos. Para este sistema en particular se utilizarán
difonemas
que corresponden a la
sección desde la mitad de un fonema hasta la mitad del siguiente. Se decidió utilizar difonemas debido a que
con una cantidad no muy grande de segmentos (aproximadamente 400) se puede generar una salida de audio
comprensible y la salida es de mejor calidad que usando fonemas simples.
Una vez que se tiene la base de datos de los segmentos, se toman los fonemas que se obtuvieron de
analizar el texto de entrada, se separan en grupos de dos para generar los difonemas requeridos [2-3]. Estos
segmentos son almacenados en un archivo nuevo en formato
wav
(formato básico que almacena la forma de la
onda de la señal entrante, estandarizado por Microsoft) que al final es reproducido.
Figura 2. Estructura básica de un sistema de síntesis de voz por concatenación.
5. Desarrollo de la aplicación
Después de describir el contexto en el cuál se desarrolló el proyecto, a continuación se presentan los pasos
seguidos para lograr la integración de un sintetizador de voz en un PDA.