


















 17 / 33
17 / 33

16
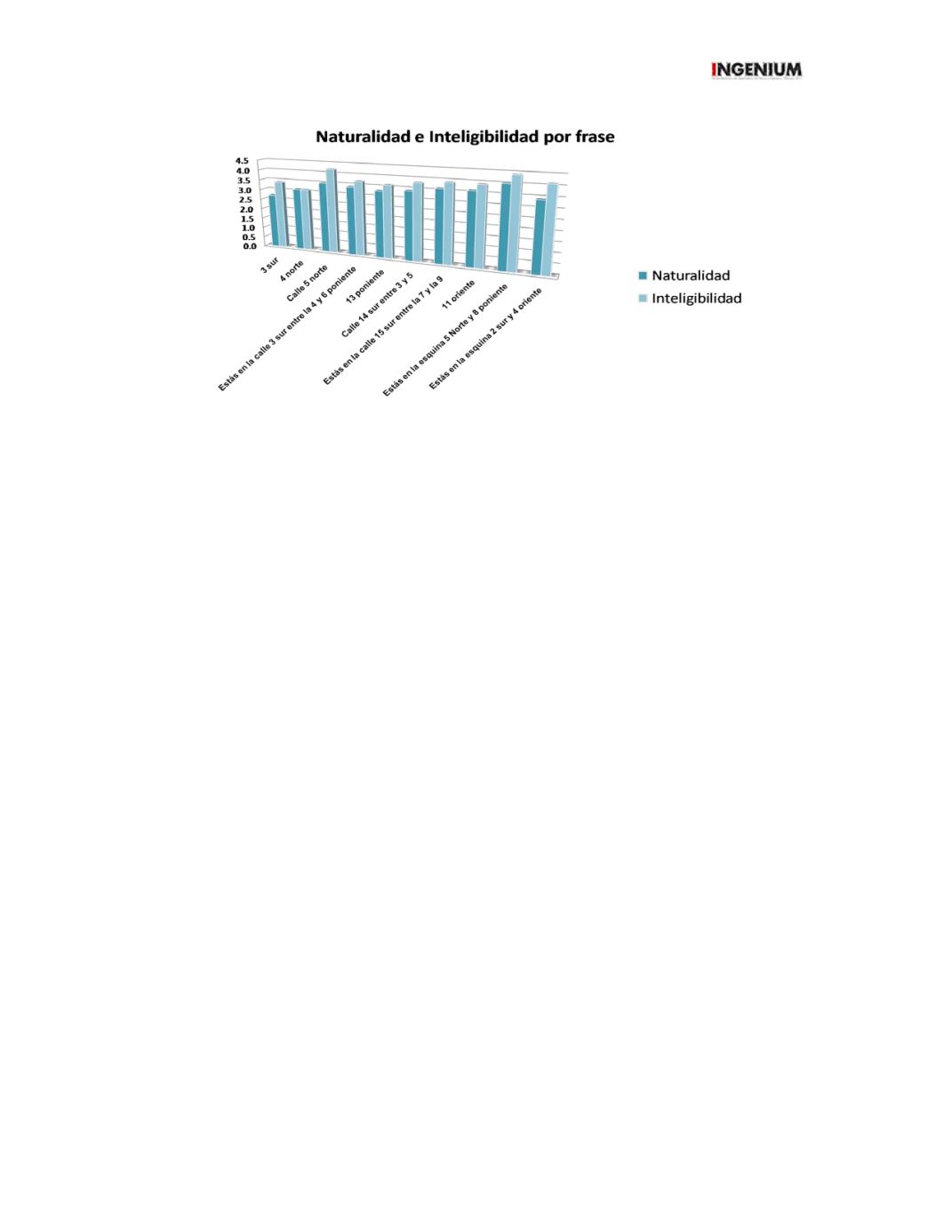
Figura 5. Grafica de naturalidad e inteligibilidad.
7. Conclusiones
Según los resultados presentados, se demuestra que la naturalidad corresponde a “voz humana poco natural
tendiente a natural” y la inteligibilidad corresponde a “prácticamente entendible”.
Actualmente el sistema
UrbvoxTTS
es funcional de acuerdo a los resultados de las pruebas. El
sistema puede generar correctamente la lectura de una palabra en español, asegurando la comunicación entre
el dispositivo y el usuario lo cual es el principal objetivo del sistema, sin embargo, podría ser mejorado
elevando los niveles de calidad.
Se detectan como formas para aumentar la calidad de voz, el aumentar la colección de difonemas y el
asegurar la transcripción fonética mediante pruebas extensivas de vocabulario detectando aquellas palabras
que no fueron reproducidas satisfactoriamente y revisando cada módulo para asegurar una salida correcta.
8. Reconocimientos
El Dr. Jesús Manuel Dorador, actualmente es jefe del Departamento de Ingeniería Mecatrónica y profesor
titular “B” de Tiempo Completo en la Facultad de Ingeniería de la UNAM, estuvo de acuerdo con apoyar el
proyecto, involucrando al Dr. Abel Herrera Camacho quien está a cargo del Laboratorio de Señales de Voz
del Posgrado de Ingeniería, en donde fue implementado un sintetizador de voz para un PDA llamado
Voz
desarrollado por el estudiante Fernando del Río Ávila, contando con las autorizaciones correspondientes
para tener acceso a la información necesaria como el código fuente, los antecedentes y la aplicación para
realizar diferentes cambios y pruebas. Agradecemos profundamente a todos ellos.
9. Referencias
[1] Lemmetty Sami, Review of Speech Synthesis Technology, Abstract of the Master’s Thesis, Helsinki,
1999.
[2] E. Keller, Improvements in Speech Synthesis, Willey and Sons, Inglaterra,2002.
[3] Dutoit Thierrry, An introduction to text-to-speech synthesis, Kluwer Academic, Holanda, 1997.